
목차
Elastic Stack
책 '엘라스틱 스택 개발부터 운영까지 - 김준영/정상운 지음'을 공부하며 정리하였습니다.
1. 역사
1.1 탄생 배경
- 'CNET 네트워크'가 상용 서비스에 적합한 수준의 높은 트래픽을 뒷받침하는 고성능 검색 엔진인 '솔라'를 개발하고 있을 시절에, '샤이배넌'은 버전 3에 이르러서 많은 부분을 재작성해 확장 가능한 검색 엔진 솔루션을 만들면 좋겠다는 생각을 하게 됨
- 처음부터 분산 환경을 위한 솔루션과, HTTP상에서 JSON으로 인터페이스를 지원하는 솔루션, 자바 이외에도 다양한 프로그래밍 언어를 지원하는 솔루션을 표방하고 작업한 배넌은 2010년 2월에 '엘라스틱 서치'를 공개함'
1.2 엘라스틱 스택으로 발전
엘라스틱 서치가 개발될 무렵, 로그스테시와 키바나 두 가지 오픈소스 프로젝트가 추가로 진행되던 중에 2012년 함께 팀을 구성하여 3개의 기술을 합친 '엘라스틱 스택'을 개발함
2. 엘라스틱 스택 구성
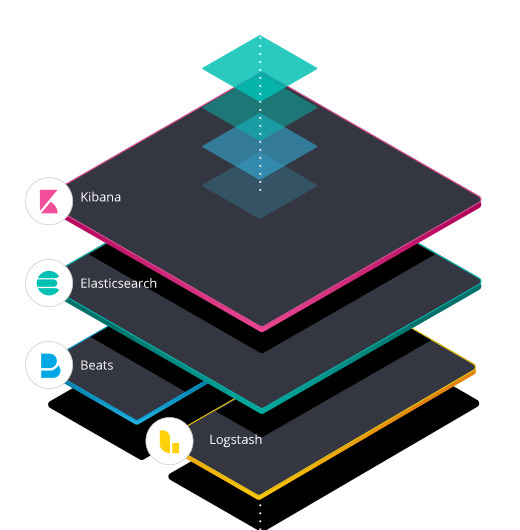
Beats : 데이터 수집Logstash : 데이터 수집Elasticsearch : 데이터 저장 & 검색 엔진Kibana : 시각화
- Beats와 Logstash는 데이터 수집하고 저장 역할
- Elasticsearch는 저장하고 분석하는 역할
- Kibana는 엘라스틱서치에 저장된 데이터를 시각화하고 모니터링하는 역할
- 필요에 따라 Kibana를 제외한 엘라스틱 스택 나머지 구성요소만으로 개별적인 빅데이터 파이프라인의 일부가 될 수 있음
2.1 Elasticsearch (분산 검색 엔진)
(1) 특징
- 검색엔진
- 내부적으로 각 도큐먼트를 인덱싱하고 빠르게 검색하는데 사용하는 기술로, 해당 검색 엔진을 이용해 구글과 네이버 같은 서비스를 만듦
- 텍스트나 도큐먼트 경우, 인덱싱 시점에 분석을 거쳐 용어 단위로 분해되고 역인덱스 사전 구축
- 숫자나 키워드 타입의 경우,엘라스틱서치 집계를 위해 집계에 최적화된 컬럼 기반 자료구조를 저장
=> 빠른 검색과 좋은 집계 성능
(엘라스틱서치가 검색 엔진인 동시에 데이터베이스이기 때문이다.)
- 모든 레코드를 JSON 도큐먼트 형태로 입력/관리함
- 쿼리로 원하는 결과 반환함
- 숫자, 날짜, IP 주소, 지리 정보 등 다양한 데이터 타입에 최적화됨
- '스코어링' (연관도에 따른 정렬) 제공
- 검색어에 대한 유사도 스코어를 기반으로 한 정렬 제공
- 다양한 스코어링 방법이 있어 사용자화 가능
(2) 장점
- 분산 시스템으로서 엘라스틱서치는 복수의 루씬 인스턴스를 병렬 배치하고, 분산 처리하여 검색 속도를 무한히 확장 가능
- 노드 간 복제 기능을 통해 일부 노드가 다운되더라도 무한히 확장 가능
- 모든 통신을 REST API를 이용하도록 만들어 프로그래밍 언어와 무관하게 사용 가능
(3) 단점
- 저장공간이 크게 압축되지 않고 시스템 리소소를 많이 사용
- DSL(Domain Specific Language)쿼리를 채용하는데 JOIN쿼리가 어렵기 때문에 반정규화를 기본으로 모델링해야함
- 인덱스가 불변의 자료구조라 도큐먼트를 수정/삭제 시 비용이 듦
=> 하지만 단점들이 검색 성능을 끌어올리기 위해 트레이드오프가 이뤄졌기 때문에 용인되는 제약들임
2.2 Kibana (시각화/Elasticsearch 관리 도구)
(1) 특징
- Elasticsearch 기반의 시각화 도구
- 라인 차트, 파이 차트 등 테이블, 지도 등 다양한 시각화 요소들을 클릭들로 쉽게 구성 가능
- 마음대로 화면 배치하고 실시간 업데이트 할 수 있는 대시보드 기능. 대시보드에서 실시간 모니터링과 데이터 분석가능
- ex. 실시간 인덱싱되는 로그 지속적 확인 및 검색 가능, 애플리케이션 성능 모니터링을 위한 APM과 보안 이벤트를 관제할 수 있는 SIEM 솔루션 적용 가능
- Elasticsearch의 UI
- 엘라스틱서치에 대한 대부분의 관리 기능, API를 실행할 수 있는 콘솔, 솔루션 페이지들, 스택의 각 구성요소들을 위한 모니터링 페이지 등 제공
2.3 Logstash (이벤트 수집과 정제 도구)
(1) 특징
- 다양한 소스로부터 로그 수집 (from 로그, 메트릭, 웹 애플리케이션 등)
- 필터 기능으로 비정형이나 반정형 데이터를 분석하기 쉬운 형태로 정제 가능
- 다양한 플랫폼으로 정제된 데이터 보낼 수 잇음
- 형식 무관하게 동적으로 수집,변환,전송하는 구조로 구성됨
- 비구조적인 데이터에서 구조를 도출 가능 (ex. IP 주소에서 위치 정보 좌표 해독, 민감한 필드 익명화 및 제외 등)
- 엘라스틱서치와 최고의 궁합
- 엘라스틱서치의 인덱싱 성능을 최적화하기 위한 배치 처리와 병렬 처리 가능
- 영속적인 큐를 사용해 현재 처리 중인 이벤트의 최소 1회 전송 보장
- 유동적인 처리 방식으로 인해 수집 중인 데이터 양이 급증하는 부하 상황에서도 안정성 보장해줌
2.4 Beats (엣지 단의 경량 수집 도구)
(1) 특징
- 경량 수집기
- 이벤트 정보를 수집하기 위해 서비스의 호스트에 수집기를 설치해야 되는데, Logstash는 무겁기 때문에 활용도가 떨어짐. Beats를 이용하여 각 서비스 호스트에 비교적 부담없이 설치할 수 있음
- 데이터 수집을 위해 용도별 최적화된 경량 에이전트로 제공되며, 특성과 성격에 맞는 다양한 비트들 존재
- 파일비트, 메트릭 비트 등 특정 목적(ex. 로그수집, 시스템 지표 수집)에 최적화된 에이전트
- 보통 Logstash와 혼합해서 많이 사용함. Beats에서 각 서비스 호스트의 정보 수집하고, Logstash에서 이를 취합/가공해 Elasticsearch로 전송하는 구조
3. 엘라스틱 스택 용도
- 전문 검색 엔진
- 전문을 용어 단위로 분석해 인덱싱해두고, 이를 기반으로 검색을 수행하는
역인덱싱기법이 많이 활용됨 - 용어 분석을 위한 다양한 언어별 분석기가 준비되어 있고, 유사도 스코어링 등 다양한 방법 제공
- Logstash를 이용해 도큐먼트 수집 단계에서부터 도움을 줌
- 전문을 용어 단위로 분석해 인덱싱해두고, 이를 기반으로 검색을 수행하는
- 로그 통합 분석
- 여러 장비와 서비스에서 발생하는 로그들을 통합하고 검색하는데 최적화된 솔루션
- File Beats의 내장된 모듈을 이용해 별도 설정 없이 빠르게 로그 수집 가능
- 커스텀 애플리케이션에서 발생한 로그의 경우 Logstash의 필터 기능이나 Elasticsearch의 수집 파이프라인 기능으로 정제 가능
- Elasticsearch는 로그 원문 빠른 검색 후 하이라이트가 가능하며, 날짜나 수치의 범위 조회, IP 대역 조회 등 로그 분석에 큰 도움됨
- Elasticsearch에 저장된 데이터들을 쉽게 교차 분석이나 연관 분석 가능 (인덱스 패턴으로 한 번에 여러 인덱스에서 동시에 조회 가능하기 때문)
- 로그 수집 시, Beats의 ECS(Elastic Common Schema) 구조에 맞추면 엘라스틱 스택의 각종 기능과 손쉬운 연계 가능
- 보안 이벤트 분석
- 엘라스틱서치의 실시간 검색 성능 & 비츠의 장비들의 각종 이벤트 수집 & ECS에 의해 통일된 스키마 기반 원활한 연관 분석 & 키바나에서 제공되는 SIEM & 지도 그래프 등은 보안 이벤트 분석에 도움을 줌
- 애플리케이션 성능 분석
- 엘라스틱 스택의 애플리케이션 성능 모니터링 도구인 APM은 프로그래밍 언어별 에이전트를 통해 성능 지표 수집을 돕고 분석을 위한 UI 제공함
- 머신러닝
- 유료 라이선스 구매 시 사용할 수 있는 기능으로, 엘라스틱서치의 데이터를 비지도형 머신러닝 기법을 활용해 패턴 발견 가능
4. 실제 사용 사례
- Uber의 대규모 실시간 데이터 통찰 플랫폼 'Gairos'
Apache Kafka Topic → Gairos Collect Pipeline → Elasticsaerch ↔ Gairos Query service ↕ Apache Hive/Presto long-term Data- Kafka와 연동
- Beats에서 수집한 각 장비의 이벤트를 Kafka로 전송 → 이를 Logstash로 다시 읽기 or Kafka에 저장된 다른 시스템의 이벤트를 Elasticsearch로 읽기 등
- 하둡 생태계와 연동
- es-hadoop 모듈을 이용해 Spark에서 Elasticsearch API를 이용하여 도큐먼트 읽거나 인덱싱 등 상호작용 수행 가능
- 관계형 데이터베이스와 연동
- 기존의 관계형 DB에 저장된 데이터를 인덱싱하거나 입력받은 이벤트에 정보를 주입하는 등 여러 용도로 사용됨
5. 유사 제품 군
- Elasticsearch -- Solr
- Logstash/Beats -- Fluentd
- Kibana -- Grafana, Tableau
- Elastic Stack -- Splunk
'#️⃣ Data Engineering > ELK Stack' 카테고리의 다른 글
| [ELK] Beats란? (0) | 2023.02.14 |
|---|
Elastic Stack
책 '엘라스틱 스택 개발부터 운영까지 - 김준영/정상운 지음'을 공부하며 정리하였습니다.
1. 역사
1.1 탄생 배경
- 'CNET 네트워크'가 상용 서비스에 적합한 수준의 높은 트래픽을 뒷받침하는 고성능 검색 엔진인 '솔라'를 개발하고 있을 시절에, '샤이배넌'은 버전 3에 이르러서 많은 부분을 재작성해 확장 가능한 검색 엔진 솔루션을 만들면 좋겠다는 생각을 하게 됨
- 처음부터 분산 환경을 위한 솔루션과, HTTP상에서 JSON으로 인터페이스를 지원하는 솔루션, 자바 이외에도 다양한 프로그래밍 언어를 지원하는 솔루션을 표방하고 작업한 배넌은 2010년 2월에 '엘라스틱 서치'를 공개함'
1.2 엘라스틱 스택으로 발전
엘라스틱 서치가 개발될 무렵, 로그스테시와 키바나 두 가지 오픈소스 프로젝트가 추가로 진행되던 중에 2012년 함께 팀을 구성하여 3개의 기술을 합친 '엘라스틱 스택'을 개발함
2. 엘라스틱 스택 구성
Beats : 데이터 수집Logstash : 데이터 수집Elasticsearch : 데이터 저장 & 검색 엔진Kibana : 시각화
- Beats와 Logstash는 데이터 수집하고 저장 역할
- Elasticsearch는 저장하고 분석하는 역할
- Kibana는 엘라스틱서치에 저장된 데이터를 시각화하고 모니터링하는 역할
- 필요에 따라 Kibana를 제외한 엘라스틱 스택 나머지 구성요소만으로 개별적인 빅데이터 파이프라인의 일부가 될 수 있음
2.1 Elasticsearch (분산 검색 엔진)
(1) 특징
- 검색엔진
- 내부적으로 각 도큐먼트를 인덱싱하고 빠르게 검색하는데 사용하는 기술로, 해당 검색 엔진을 이용해 구글과 네이버 같은 서비스를 만듦
- 텍스트나 도큐먼트 경우, 인덱싱 시점에 분석을 거쳐 용어 단위로 분해되고 역인덱스 사전 구축
- 숫자나 키워드 타입의 경우,엘라스틱서치 집계를 위해 집계에 최적화된 컬럼 기반 자료구조를 저장
=> 빠른 검색과 좋은 집계 성능
(엘라스틱서치가 검색 엔진인 동시에 데이터베이스이기 때문이다.)
- 모든 레코드를 JSON 도큐먼트 형태로 입력/관리함
- 쿼리로 원하는 결과 반환함
- 숫자, 날짜, IP 주소, 지리 정보 등 다양한 데이터 타입에 최적화됨
- '스코어링' (연관도에 따른 정렬) 제공
- 검색어에 대한 유사도 스코어를 기반으로 한 정렬 제공
- 다양한 스코어링 방법이 있어 사용자화 가능
(2) 장점
- 분산 시스템으로서 엘라스틱서치는 복수의 루씬 인스턴스를 병렬 배치하고, 분산 처리하여 검색 속도를 무한히 확장 가능
- 노드 간 복제 기능을 통해 일부 노드가 다운되더라도 무한히 확장 가능
- 모든 통신을 REST API를 이용하도록 만들어 프로그래밍 언어와 무관하게 사용 가능
(3) 단점
- 저장공간이 크게 압축되지 않고 시스템 리소소를 많이 사용
- DSL(Domain Specific Language)쿼리를 채용하는데 JOIN쿼리가 어렵기 때문에 반정규화를 기본으로 모델링해야함
- 인덱스가 불변의 자료구조라 도큐먼트를 수정/삭제 시 비용이 듦
=> 하지만 단점들이 검색 성능을 끌어올리기 위해 트레이드오프가 이뤄졌기 때문에 용인되는 제약들임
2.2 Kibana (시각화/Elasticsearch 관리 도구)
(1) 특징
- Elasticsearch 기반의 시각화 도구
- 라인 차트, 파이 차트 등 테이블, 지도 등 다양한 시각화 요소들을 클릭들로 쉽게 구성 가능
- 마음대로 화면 배치하고 실시간 업데이트 할 수 있는 대시보드 기능. 대시보드에서 실시간 모니터링과 데이터 분석가능
- ex. 실시간 인덱싱되는 로그 지속적 확인 및 검색 가능, 애플리케이션 성능 모니터링을 위한 APM과 보안 이벤트를 관제할 수 있는 SIEM 솔루션 적용 가능
- Elasticsearch의 UI
- 엘라스틱서치에 대한 대부분의 관리 기능, API를 실행할 수 있는 콘솔, 솔루션 페이지들, 스택의 각 구성요소들을 위한 모니터링 페이지 등 제공
2.3 Logstash (이벤트 수집과 정제 도구)
(1) 특징
- 다양한 소스로부터 로그 수집 (from 로그, 메트릭, 웹 애플리케이션 등)
- 필터 기능으로 비정형이나 반정형 데이터를 분석하기 쉬운 형태로 정제 가능
- 다양한 플랫폼으로 정제된 데이터 보낼 수 잇음
- 형식 무관하게 동적으로 수집,변환,전송하는 구조로 구성됨
- 비구조적인 데이터에서 구조를 도출 가능 (ex. IP 주소에서 위치 정보 좌표 해독, 민감한 필드 익명화 및 제외 등)
- 엘라스틱서치와 최고의 궁합
- 엘라스틱서치의 인덱싱 성능을 최적화하기 위한 배치 처리와 병렬 처리 가능
- 영속적인 큐를 사용해 현재 처리 중인 이벤트의 최소 1회 전송 보장
- 유동적인 처리 방식으로 인해 수집 중인 데이터 양이 급증하는 부하 상황에서도 안정성 보장해줌
2.4 Beats (엣지 단의 경량 수집 도구)
(1) 특징
- 경량 수집기
- 이벤트 정보를 수집하기 위해 서비스의 호스트에 수집기를 설치해야 되는데, Logstash는 무겁기 때문에 활용도가 떨어짐. Beats를 이용하여 각 서비스 호스트에 비교적 부담없이 설치할 수 있음
- 데이터 수집을 위해 용도별 최적화된 경량 에이전트로 제공되며, 특성과 성격에 맞는 다양한 비트들 존재
- 파일비트, 메트릭 비트 등 특정 목적(ex. 로그수집, 시스템 지표 수집)에 최적화된 에이전트
- 보통 Logstash와 혼합해서 많이 사용함. Beats에서 각 서비스 호스트의 정보 수집하고, Logstash에서 이를 취합/가공해 Elasticsearch로 전송하는 구조
3. 엘라스틱 스택 용도
- 전문 검색 엔진
- 전문을 용어 단위로 분석해 인덱싱해두고, 이를 기반으로 검색을 수행하는
역인덱싱기법이 많이 활용됨 - 용어 분석을 위한 다양한 언어별 분석기가 준비되어 있고, 유사도 스코어링 등 다양한 방법 제공
- Logstash를 이용해 도큐먼트 수집 단계에서부터 도움을 줌
- 전문을 용어 단위로 분석해 인덱싱해두고, 이를 기반으로 검색을 수행하는
- 로그 통합 분석
- 여러 장비와 서비스에서 발생하는 로그들을 통합하고 검색하는데 최적화된 솔루션
- File Beats의 내장된 모듈을 이용해 별도 설정 없이 빠르게 로그 수집 가능
- 커스텀 애플리케이션에서 발생한 로그의 경우 Logstash의 필터 기능이나 Elasticsearch의 수집 파이프라인 기능으로 정제 가능
- Elasticsearch는 로그 원문 빠른 검색 후 하이라이트가 가능하며, 날짜나 수치의 범위 조회, IP 대역 조회 등 로그 분석에 큰 도움됨
- Elasticsearch에 저장된 데이터들을 쉽게 교차 분석이나 연관 분석 가능 (인덱스 패턴으로 한 번에 여러 인덱스에서 동시에 조회 가능하기 때문)
- 로그 수집 시, Beats의 ECS(Elastic Common Schema) 구조에 맞추면 엘라스틱 스택의 각종 기능과 손쉬운 연계 가능
- 보안 이벤트 분석
- 엘라스틱서치의 실시간 검색 성능 & 비츠의 장비들의 각종 이벤트 수집 & ECS에 의해 통일된 스키마 기반 원활한 연관 분석 & 키바나에서 제공되는 SIEM & 지도 그래프 등은 보안 이벤트 분석에 도움을 줌
- 애플리케이션 성능 분석
- 엘라스틱 스택의 애플리케이션 성능 모니터링 도구인 APM은 프로그래밍 언어별 에이전트를 통해 성능 지표 수집을 돕고 분석을 위한 UI 제공함
- 머신러닝
- 유료 라이선스 구매 시 사용할 수 있는 기능으로, 엘라스틱서치의 데이터를 비지도형 머신러닝 기법을 활용해 패턴 발견 가능
4. 실제 사용 사례
- Uber의 대규모 실시간 데이터 통찰 플랫폼 'Gairos'
Apache Kafka Topic → Gairos Collect Pipeline → Elasticsaerch ↔ Gairos Query service ↕ Apache Hive/Presto long-term Data- Kafka와 연동
- Beats에서 수집한 각 장비의 이벤트를 Kafka로 전송 → 이를 Logstash로 다시 읽기 or Kafka에 저장된 다른 시스템의 이벤트를 Elasticsearch로 읽기 등
- 하둡 생태계와 연동
- es-hadoop 모듈을 이용해 Spark에서 Elasticsearch API를 이용하여 도큐먼트 읽거나 인덱싱 등 상호작용 수행 가능
- 관계형 데이터베이스와 연동
- 기존의 관계형 DB에 저장된 데이터를 인덱싱하거나 입력받은 이벤트에 정보를 주입하는 등 여러 용도로 사용됨
5. 유사 제품 군
- Elasticsearch -- Solr
- Logstash/Beats -- Fluentd
- Kibana -- Grafana, Tableau
- Elastic Stack -- Splunk
'#️⃣ Data Engineering > ELK Stack' 카테고리의 다른 글
| [ELK] Beats란? (0) | 2023.02.14 |
|---|