
1 | 이벤트시간 윈도우, 워터마크
1-1 | 이벤트 시간 윈도우 (event-time window)
📌 이벤트 시간 윈도우란, 행의 이벤트 시간이 속하는 윈도우별로 집계(그룹화)하는 것을 말한다.
이벤트 시간 윈도우는 '이벤트 시간 처리' 개념에서 비롯된 것이다.
이벤트 시간 윈도우란 행의 이벤트 시간이 속하는 윈도우 별로 집계 즉 그룹화 하는 것을 말한다.
있는데 이를 쉽게 풀어서 설명하면, 이벤트가 실제로 발생한 이벤트 시간대 별로 스트리밍으로 들어온 데이터를 카운트하는 것을 말한다. 예를 들면 계속해서 스트리밍으로 들어오는 이벤트가 있다고 가정하면, 10분 간격으로 이벤트들을 이벤트 생성 시간 기준으로 이 이벤트들을 집계 하는 것을 한다.
여기 설명에서 행이라고 지칭한 이유는 structured streaming 은 테이블형식으로 스트리밍 되는데, 테이블의 행이 스트리밍 되어 온 데이터 하나씩을 지칭하는 것이기 때문이다.
+ '이벤트 시간 처리' 란?
이벤트가 생성된 시간을 기준으로 정보를 분석해 늦게 도착한 이벤트까지 처리할 수 있게 해줌
[ 구분 ]
- 이벤트 시간 : 이벤트가 실제로 발생한 시간
- 데이터에 기록된 시간
- 데이터 마다 이벤트 시간을 비교할 때, 지연되거나 무작위로 도착한 이벤트가 있으므로 스트리밍 처리 시 이를 제어할 수 있어야 된다.
- 처리시간 : 이벤트가 시스템에 도착하거나 처리된 시간
- 스트림 처리 시스템이 데이터를 실제 수신한 시간
- 처리 시간은 세부 구현과 관련된 내용과 관련됨
- 처리시간은 이벤트 시간처럼 외부 시스템에서 제공하는 것이 아니라 스트리밍 시스템이 제공하는 속성이므로 순서가 뒤섞이지 않음
[ 예시 ]
한국에 데이터센터가 있다고 가정하자.
일본에서 발생한 이벤트와 미국에서 발생한 이벤트가 같은 시간에 다른 장소에 발생했다면, 일본에서 이벤트가 미국의 이벤트보다 먼저 데이터 센터에 도착한다.
이를 처리 시간으로 데이터 분석하면 일본의 이벤트가 미국 이벤트 보다 먼저 발생한 것으로 나타나므로 정상적이지 않다.
이를 이벤트 시간 기준으로 분석하면 같은 시간 이벤트로 처리 가능하다.
즉, 처리 시스템의 이벤트 순서는 이벤트 시간 순으로 정렬되어 있다고 보장 할 수 없으므로, 이벤트 시간 기준의 처리가 필요하다. 처리시스템에 도착한 시간 대신 스트림 데이터가 가진 시간 정보를 참조한다.
1) 예시 - 슬라이딩 윈도우
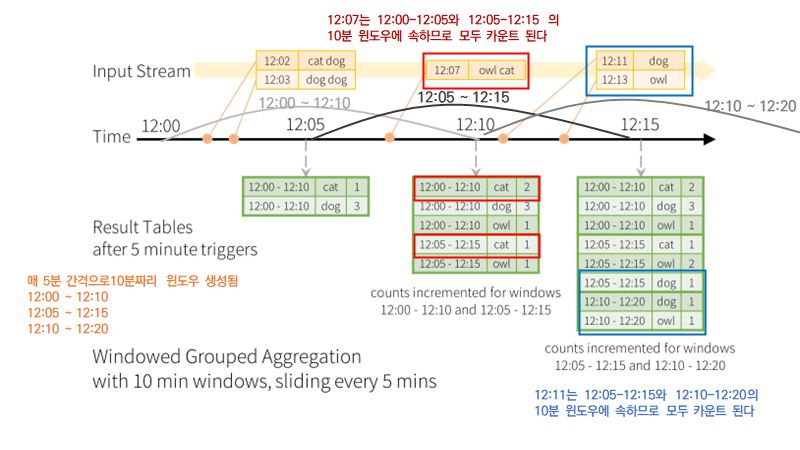
매 5분 간격으로10분짜리 윈도우 생성됨
- 12:00 ~ 12:10 12:05 ~ 12:15 12:10 ~ 12:20
카운트는 그룹핑 키(word)와 윈도우(이벤트 시간)에 모두 인덱싱됨
- 12:07는 12:00-12:05와 12:05-12:15 의 10분 윈도우에 속하므로 모두 카운트 된다
- 12:11는 12:05-12:15와 12:10-12:20의 10분 윈도우에 속하므로 모두 카운트 된다
위의 예시는 이벤트 시간 윈도우 중 슬라이딩 윈도우를 이용한 워드카운트 예시이다.
들어오는 스트림 각 행에 이벤트 시간과 단어가 있다고 해보자. 목표는 단어 카운트를 매 5분간격으로 업데이트하는 10분 짜리 윈도우를 이용하여 해당 윈도우 내에 단어수를 계산하는 것이다.
매 5분 간격으로 10분짜리 윈도우가 생성된다면, 12:00 ~ 12:10, 12:05 ~ 12:15, 12:10 ~ 12:20 이렇게 윈도우가 있다.
여기서 12시~12시 10분 윈도우는 12시 이후와 12시 10분 이전 사이에 도착한 것을 의미한다. 그래서 위의 그림을 보면, 첫번째 input stream에 12시 2분과 3분에 들어온 cat dog 그리고 dog, dog이 12시랑 12시 10분 윈도우에 cat과 dog 1개 3개씩 집계된 것을 확인할 수 있다.
만약 12시 7분에 단어가 들어왔다면 12시-12시 10분 윈도우와 12:5분 12시 15분 윈도우 두 개 모두 카운트된다.
12시 11분에 들어온 단어 역시 2개의 윈도우에 속하므로 2개 모두 카운트 되는 것을 확인할 수 있다.
2) 시간 윈도우 종류
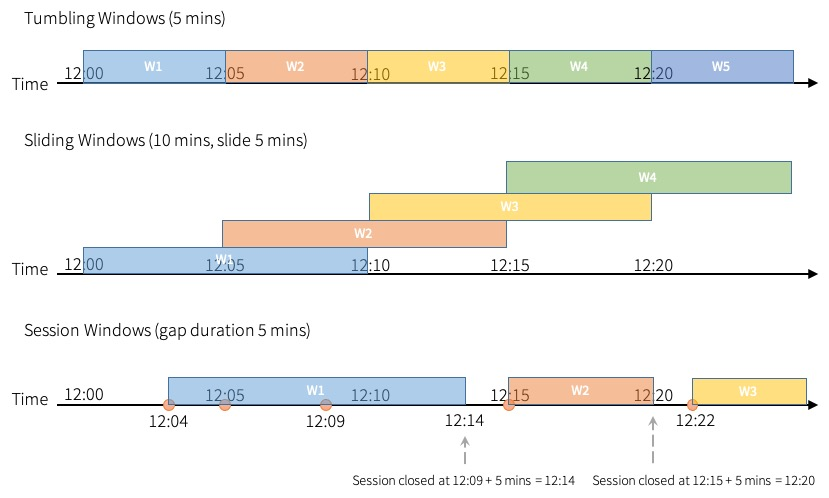
- 텀블링 윈도우 : 고정된 크기로 겹치지 않는 연속된 시간 간격. 하나의 입력은 하나의 윈도우에만 바인딩됨
- 슬라이딩 윈도우 : 텀블링 윈도우와 유사하게 고정된 크기의 윈도우를 갖고 있지만, 슬라이드의 기간이 창의 지속 기간 보다 작으면 겹칠 수 있다. 이럴 경우 하나의 입력은 여러개의 윈도우에 바인딩 된다.
- 세션 윈도우 : 윈도우 크기가 입력크기에 따라 동적으로 변함.
- 세션 윈도우는 입력이 들어왔을 때 시작되며, 입력이 주어지는 갭 기간 동안 확장된다.
- 세션윈도우는 마지막 입력 값을 받고, 갭 기간동안 더 이상 입력값이 없다면 닫힌다.
3) 코드
텀블링/슬라이딩 윈도우는 window 함수가, 세션 윈도우는 session_window 함수가 이용된다.
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()위에서 봤던 워드카운팅 예시 코드로, window 함수를 써서 매 5분간격으로 업데이트하는 10분 짜리 슬라이딩 윈도우를 구현한 것이다.
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()세션 윈도우 코드로, 5분짜리 윈도우를 사용하는 예시이다.
1-2 | 지연데이터 워터마크 처리
1) 예시
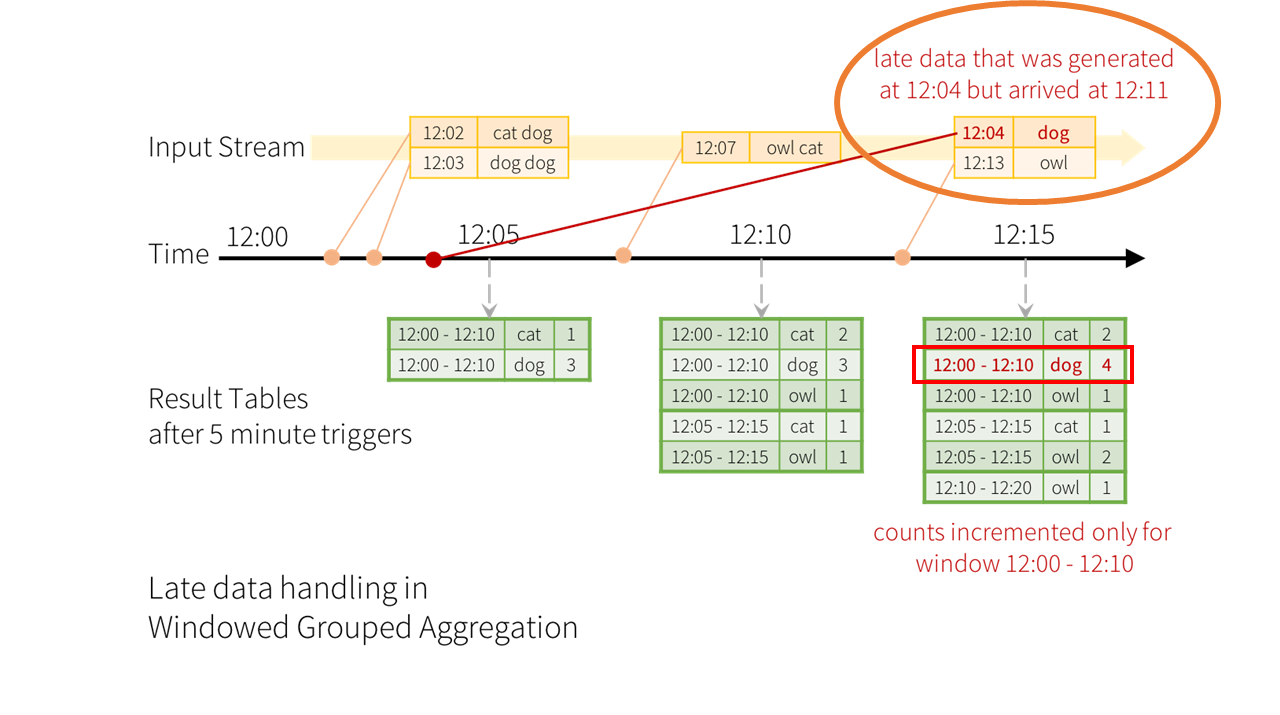
만약, 12:11에 12:04에 생성된 데이터가 늦게 수신된다고 하면, 해당 윈도우 시간(12:00 ~ 12:10)에 집계되어야 한다.
⇒ 지연 데이터가 이전 윈도우의 집계를 정확히 업데이트 할 수 있게, 오랜 기간동안 이전의 부분 집계에 대한 중간 상태를 유지해야 한다.
하지만, 해당 쿼리가 며칠 동안 걸쳐 장기간 실행된다면, 시스템에 누적되는 메모리가 과부하가 올 것이다. → 워터마킹으로 제한을 둔다
⇒ 즉, 워터마킹이란 spark 엔진이 현재 이벤트 시간을 자동으로 추적하고 이전 상태들을 정리할 수 있도록 한 기능이다.
다음은 지연데이터를 위한 워터 마크 처리를 알아보자.
아까 위에서 봤던 워드 카운팅 예제에서 만약, 12:11분에 12:04분에 생성된 데이터(지연 데이터)가 늦게 수신된다고 가정해보자.
해당 데이터는 이벤트 시간에 따라 윈도우 시간(12:00 ~ 12:10)에 집계되어야 하는데, 현재의 12시 11분이면 12시:05~12:15분 그리고 12:10~12:20 윈도우 시간대 이므로 12시 4분을 기록하는 윈도우는 이미 지나온 상황이다.
이렇게 지연된 데이터를 처리하기 위해서는, 오랜 기간동안 이전의 부분 집계에 대한 중간 상태를 유지해야된다.
하지만, 해당 쿼리가 며칠 동안 걸쳐 장기간 실행된다면, 오랜 기간동안 중간 상태를 유지하는 것은 시스템에 누적되는 메모리가 과부하가 올 것이다.
이때 워터마킹을 이용하여 제한을 두는 동시에 이전 중간 상태를 일정 기간동안 유지할 수있게 해준다.
즉, 워터마킹이란 spark 엔진이 현재 이벤트 시간을 자동으로 추적하고 이전 상태들을 정리할 수 있도록 한 기능이다.
2) 코드
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()- 지연되는 데이터를 허용하는 시간 임계값 : 10분
- ⇒ 즉, 10분 이내의 이벤트만 받아들인다. 만약 워터 마크를 지정하지 않으면 전체 윈도우 데이터를 영원히 유지하며 결과를 갱신하기 때문에 시스템 부하가 크다.
참고
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Structured Streaming Programming Guide - Spark 3.3.0 Documentation
Structured Streaming Programming Guide Overview Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on s
spark.apache.org
<Spark : The Definitive Guide 스파크 완벽가이드>빌 체임버스, 마테이 자하리아 지음
'#️⃣ Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark Streaming - Twitter 해시태그 분석 (2) (0) | 2022.10.07 |
|---|---|
| [Spark] Spark Streaming - Twitter 해시태그 분석 (1) (0) | 2022.10.07 |
| [Spark] Spark란 + 실습 (추가 정리) (0) | 2022.10.06 |
| [Spark] Ubuntu 21.04에 Spark 설치하기 (0) | 2022.03.14 |
| [Hadoop] Spark란 + 실습 (0) | 2022.03.11 |
1 | 이벤트시간 윈도우, 워터마크
1-1 | 이벤트 시간 윈도우 (event-time window)
📌 이벤트 시간 윈도우란, 행의 이벤트 시간이 속하는 윈도우별로 집계(그룹화)하는 것을 말한다.
이벤트 시간 윈도우는 '이벤트 시간 처리' 개념에서 비롯된 것이다.
이벤트 시간 윈도우란 행의 이벤트 시간이 속하는 윈도우 별로 집계 즉 그룹화 하는 것을 말한다.
있는데 이를 쉽게 풀어서 설명하면, 이벤트가 실제로 발생한 이벤트 시간대 별로 스트리밍으로 들어온 데이터를 카운트하는 것을 말한다. 예를 들면 계속해서 스트리밍으로 들어오는 이벤트가 있다고 가정하면, 10분 간격으로 이벤트들을 이벤트 생성 시간 기준으로 이 이벤트들을 집계 하는 것을 한다.
여기 설명에서 행이라고 지칭한 이유는 structured streaming 은 테이블형식으로 스트리밍 되는데, 테이블의 행이 스트리밍 되어 온 데이터 하나씩을 지칭하는 것이기 때문이다.
+ '이벤트 시간 처리' 란?
이벤트가 생성된 시간을 기준으로 정보를 분석해 늦게 도착한 이벤트까지 처리할 수 있게 해줌
[ 구분 ]
- 이벤트 시간 : 이벤트가 실제로 발생한 시간
- 데이터에 기록된 시간
- 데이터 마다 이벤트 시간을 비교할 때, 지연되거나 무작위로 도착한 이벤트가 있으므로 스트리밍 처리 시 이를 제어할 수 있어야 된다.
- 처리시간 : 이벤트가 시스템에 도착하거나 처리된 시간
- 스트림 처리 시스템이 데이터를 실제 수신한 시간
- 처리 시간은 세부 구현과 관련된 내용과 관련됨
- 처리시간은 이벤트 시간처럼 외부 시스템에서 제공하는 것이 아니라 스트리밍 시스템이 제공하는 속성이므로 순서가 뒤섞이지 않음
[ 예시 ]
한국에 데이터센터가 있다고 가정하자.
일본에서 발생한 이벤트와 미국에서 발생한 이벤트가 같은 시간에 다른 장소에 발생했다면, 일본에서 이벤트가 미국의 이벤트보다 먼저 데이터 센터에 도착한다.
이를 처리 시간으로 데이터 분석하면 일본의 이벤트가 미국 이벤트 보다 먼저 발생한 것으로 나타나므로 정상적이지 않다.
이를 이벤트 시간 기준으로 분석하면 같은 시간 이벤트로 처리 가능하다.
즉, 처리 시스템의 이벤트 순서는 이벤트 시간 순으로 정렬되어 있다고 보장 할 수 없으므로, 이벤트 시간 기준의 처리가 필요하다. 처리시스템에 도착한 시간 대신 스트림 데이터가 가진 시간 정보를 참조한다.
1) 예시 - 슬라이딩 윈도우
매 5분 간격으로10분짜리 윈도우 생성됨
- 12:00 ~ 12:10 12:05 ~ 12:15 12:10 ~ 12:20
카운트는 그룹핑 키(word)와 윈도우(이벤트 시간)에 모두 인덱싱됨
- 12:07는 12:00-12:05와 12:05-12:15 의 10분 윈도우에 속하므로 모두 카운트 된다
- 12:11는 12:05-12:15와 12:10-12:20의 10분 윈도우에 속하므로 모두 카운트 된다
위의 예시는 이벤트 시간 윈도우 중 슬라이딩 윈도우를 이용한 워드카운트 예시이다.
들어오는 스트림 각 행에 이벤트 시간과 단어가 있다고 해보자. 목표는 단어 카운트를 매 5분간격으로 업데이트하는 10분 짜리 윈도우를 이용하여 해당 윈도우 내에 단어수를 계산하는 것이다.
매 5분 간격으로 10분짜리 윈도우가 생성된다면, 12:00 ~ 12:10, 12:05 ~ 12:15, 12:10 ~ 12:20 이렇게 윈도우가 있다.
여기서 12시~12시 10분 윈도우는 12시 이후와 12시 10분 이전 사이에 도착한 것을 의미한다. 그래서 위의 그림을 보면, 첫번째 input stream에 12시 2분과 3분에 들어온 cat dog 그리고 dog, dog이 12시랑 12시 10분 윈도우에 cat과 dog 1개 3개씩 집계된 것을 확인할 수 있다.
만약 12시 7분에 단어가 들어왔다면 12시-12시 10분 윈도우와 12:5분 12시 15분 윈도우 두 개 모두 카운트된다.
12시 11분에 들어온 단어 역시 2개의 윈도우에 속하므로 2개 모두 카운트 되는 것을 확인할 수 있다.
2) 시간 윈도우 종류
- 텀블링 윈도우 : 고정된 크기로 겹치지 않는 연속된 시간 간격. 하나의 입력은 하나의 윈도우에만 바인딩됨
- 슬라이딩 윈도우 : 텀블링 윈도우와 유사하게 고정된 크기의 윈도우를 갖고 있지만, 슬라이드의 기간이 창의 지속 기간 보다 작으면 겹칠 수 있다. 이럴 경우 하나의 입력은 여러개의 윈도우에 바인딩 된다.
- 세션 윈도우 : 윈도우 크기가 입력크기에 따라 동적으로 변함.
- 세션 윈도우는 입력이 들어왔을 때 시작되며, 입력이 주어지는 갭 기간 동안 확장된다.
- 세션윈도우는 마지막 입력 값을 받고, 갭 기간동안 더 이상 입력값이 없다면 닫힌다.
3) 코드
텀블링/슬라이딩 윈도우는 window 함수가, 세션 윈도우는 session_window 함수가 이용된다.
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()위에서 봤던 워드카운팅 예시 코드로, window 함수를 써서 매 5분간격으로 업데이트하는 10분 짜리 슬라이딩 윈도우를 구현한 것이다.
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()세션 윈도우 코드로, 5분짜리 윈도우를 사용하는 예시이다.
1-2 | 지연데이터 워터마크 처리
1) 예시
만약, 12:11에 12:04에 생성된 데이터가 늦게 수신된다고 하면, 해당 윈도우 시간(12:00 ~ 12:10)에 집계되어야 한다.
⇒ 지연 데이터가 이전 윈도우의 집계를 정확히 업데이트 할 수 있게, 오랜 기간동안 이전의 부분 집계에 대한 중간 상태를 유지해야 한다.
하지만, 해당 쿼리가 며칠 동안 걸쳐 장기간 실행된다면, 시스템에 누적되는 메모리가 과부하가 올 것이다. → 워터마킹으로 제한을 둔다
⇒ 즉, 워터마킹이란 spark 엔진이 현재 이벤트 시간을 자동으로 추적하고 이전 상태들을 정리할 수 있도록 한 기능이다.
다음은 지연데이터를 위한 워터 마크 처리를 알아보자.
아까 위에서 봤던 워드 카운팅 예제에서 만약, 12:11분에 12:04분에 생성된 데이터(지연 데이터)가 늦게 수신된다고 가정해보자.
해당 데이터는 이벤트 시간에 따라 윈도우 시간(12:00 ~ 12:10)에 집계되어야 하는데, 현재의 12시 11분이면 12시:05~12:15분 그리고 12:10~12:20 윈도우 시간대 이므로 12시 4분을 기록하는 윈도우는 이미 지나온 상황이다.
이렇게 지연된 데이터를 처리하기 위해서는, 오랜 기간동안 이전의 부분 집계에 대한 중간 상태를 유지해야된다.
하지만, 해당 쿼리가 며칠 동안 걸쳐 장기간 실행된다면, 오랜 기간동안 중간 상태를 유지하는 것은 시스템에 누적되는 메모리가 과부하가 올 것이다.
이때 워터마킹을 이용하여 제한을 두는 동시에 이전 중간 상태를 일정 기간동안 유지할 수있게 해준다.
즉, 워터마킹이란 spark 엔진이 현재 이벤트 시간을 자동으로 추적하고 이전 상태들을 정리할 수 있도록 한 기능이다.
2) 코드
words = ... # streaming DataFrame of schema { timestamp: Timestamp, word: String }
# Group the data by window and word and compute the count of each group
windowedCounts = words \
.withWatermark("timestamp", "10 minutes") \
.groupBy(
window(words.timestamp, "10 minutes", "5 minutes"),
words.word) \
.count()- 지연되는 데이터를 허용하는 시간 임계값 : 10분
- ⇒ 즉, 10분 이내의 이벤트만 받아들인다. 만약 워터 마크를 지정하지 않으면 전체 윈도우 데이터를 영원히 유지하며 결과를 갱신하기 때문에 시스템 부하가 크다.
참고
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Structured Streaming Programming Guide - Spark 3.3.0 Documentation
Structured Streaming Programming Guide Overview Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on s
spark.apache.org
<Spark : The Definitive Guide 스파크 완벽가이드>빌 체임버스, 마테이 자하리아 지음
'#️⃣ Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark Streaming - Twitter 해시태그 분석 (2) (0) | 2022.10.07 |
|---|---|
| [Spark] Spark Streaming - Twitter 해시태그 분석 (1) (0) | 2022.10.07 |
| [Spark] Spark란 + 실습 (추가 정리) (0) | 2022.10.06 |
| [Spark] Ubuntu 21.04에 Spark 설치하기 (0) | 2022.03.14 |
| [Hadoop] Spark란 + 실습 (0) | 2022.03.11 |