
이전에 블로그에 정리했던 글을 동아리 스터디를 위해 한 번 더 정리한 글이다.
기록을 위해 블로그에도 남긴다.
이전 정리글 :https://hyem207.tistory.com/43
[Hadoop] Spark란 + 실습
보호되어 있는 글입니다. 내용을 보시려면 비밀번호를 입력하세요.
hyem207.tistory.com
목차
1 | Spark란
2 | Spark 정의 및 등장 배경
2-1 | Spark란
2-2 | Spark 등장 배경
3| Spark Architecture
4 | Spark SQL실습
1 | Spark란

간략 소개
The most widely-used engine for scalable computing
Thousands of companies, including 80% of the Fortune 500, use Apache Spark™.Over 2,000 contributors to the open source project from industry and academia.
Amazon, Ebay, Yahoo 등에서 사용
스파크는 머신러닝 과 같은 복잡한 작업도 가능하며, 데이터 마이닝, 그래프 분석, 스트리밍 데이터도 다룰 수 있다.
자바, 스칼라, 파이썬 등의 프로그래밍 언어 지원하여 스크립트 작성함
무엇보다도 속도도 빠르고 확장 가능한 강력한 프레임워크다. "맵 리듀스와 비교시, 메모리 내에서 작동시 100배, 디스크로 접근 시에는 10배 더 빨라짐" "또한 맵리듀스는 제한적이지만, 스파크는 좀 더 유연하게 사용 가능함" "핫한 기술"
2 | Spark 정의 및 등장 배경
2-1 | Spark란
💡 " A fast and general engine for large-scale data processing" 대규모 데이터를 처리하는 빠른 엔진 (병렬 처리 오픈소스 엔진)
- 통합 컴퓨팅 엔진, 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합 (병렬 처리 오픈소스 엔진)
- 클러스터 : 두 개 이상의 노드에 걸쳐있는 여러 서버 인스턴스 그룹
1) 특징

- 빠른 처리 속도
- 단일 노트북 환경에서부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행 가능
- 빅데이터 처리 쉽게 시작 가능, 엄청난 규모의 클러스터로 확장 가능
- 다양한 프로그래밍 언어 지원
- 다양한 라이브러리 지원
- 높은 호환성
2) Spark의 철학
- 통합
- 혼합형 API를 제공하여 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있음 (다른 라이브러리의 기능을 조합)
- 스파크는 통합 엔진을 제공하면서 빠르게 빅데이터 분석 업무의 표준이 됨
- 컴퓨터 엔진
- 스파크는 통합이라는 관점을 중시하면서 컴퓨팅 엔진으로 제한해 옴
- 스파크는 데이터 연산만 수행할 뿐 영구 저장소 역할은 수행하지 않음. 대신 클라우드 기반의 저장소를 지원함.→ 이는 데이터 저장 위치에 상관없이 처리에 집중되도록 만들어 짐
- 라이브러리

- 스파크에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 올라온 다양한 외부 라이브러리를 지원함
2-2 | Spark 등장 배경
💡 첫 시작 : UC버클리 대학교에서 2009년 스파크 연구 프로젝트로 시작되어 다음 해에 UC 버클리 대학교 AMPlab 소속에서 낸 논문으로 스파크를 처음 세상에 알리게 됨 → Spark는 이후에도 꾸준히 확장 중
1) 만들어진 당시 상황
하둡 맵 리듀스는 대규모 클러스터에서 병렬로 데이터를 처리하기 위한 최초의 오픈 소스 시스템
하지만 다음과 같은 문제점이 있었음

- 맵 리듀스로 처리하려면 단계별로 맵 리듀스 잡을 개발하고 클러스터에서 각각 실행해야 하므로 매번 데이터를 처음부터 읽어야 했음
⇒ Spark 등장 : 함수형 프로그래밍 기반의 API, 새로운 엔진 기반의 API를 구현함
📢 Spark VS 맵 리듀스 속도 비교
스파크는 인메모리 기반의 처리로 맵리듀스 작업처리에 비해 디스크는 10배, 메모리 작업은 100배 빠름
원인 : 작업의 중간 결과 저장 장소
- 맵 리듀스 : 디스크
- Spark : 메모리
2) Spark의 발전
- 스파크의 첫 버전은 배치 애플리케이션만 지원하다가, 스칼라 인터프리터를 스파크에 접목하여 매우 유용한 대화형 시스템을 제공할 수 있게 됨
- → 이러한 사용에서 문제점을 정리하여 더 범용적인 컴퓨팅 플랫폼을 설계함
- 조합형 API의 핵심 아이디어
- 1.0 이전
- 초기 버전은 함수형 연산 관점에서 API 정의
- 1.0 이후
- 구조화된 데이터를 기반으로 동작하는 신규 API인 스파크 SQL 추가됨
- 이후 DataFrame, 머신러닝 파이프라인, 구조적 스트리밍 등 더 강력한 구조체 기반의 신규 API를 추가함
- 2013년에 AMPlab은 스파크가 특정 업체에 종속되는 것을 막기 위해 아파치 재단에 기부함 & 초기 팀은 프로젝트를 성장시키기 위해 '데이터브릭스'를 설립함.
3 | Spark Architecture
3-1 | Spark 기본 아키텍처

💡 Spark는 클러스터의 데이터 처리 작업을 관리하고 조율함.
*클러스터 : 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있게 만듦
구성 요소
크게 Driver와 Executer로 구성됨
클러스터 매니저 : 연산에 사용할 클러스터(자원) 관리
- 클러스터 매니저 ‘자원할당’ 흐름
- 사용자가 클러스터 매니저에 스파크 애플리케이션을 제출함 → 클러스터 매니저가 애플리케이션에 필요한 자원 할당 → 할당받은 자원으로 작업 처리
드라이버 프로세스 : 스파크 애플리케이션의 심장. 클러스터 노드 중 하나로 main() 실행
: SparkContext 객체 생성
역할 :
- 애플리케이션의 수명 주기 동안 관련 정보 모두 유지
- 사용자 프로그램/입력에 대한 응답
- 전반적인 익스큐터 프로세스 작업과 관련된 분석/배포/스케줄링 수행
익스큐터 : 드라이버 프로세스가 할당한 작업 수행
- 역할 :
- 드라이버가 할당한 코드를 실행
- 진행상황을 다시 드라이버 노드에 보고
스파크 어플리케이션
스파크 실행 프로그램
드라이버와 익스큐터로 실행되는 프로그램
SparkSession(드라이버 프로세스)로 제어함
SparkSession (SparkContext)
클러스터 매니저와 연결되는 객체
클러스터 매니저
스파크 어플리케이션의 자원 분배
유형
- StandAlone– Spark에 포함된 심플한 클러스터 매니저를 통해
- 클러스터를 쉽게 설정할 수 있습니다.
- Apache Mesos – Hadoop MapReduce도 실행할 수 있는 일반 클러스터 관리자 및 서비스 어플리케이션(권장되지 않음)
- Hadoop WARN – Hadoop 2 및 3의 리소스 관리자.
- Kubernetes – 도입, 확장, 확장 자동화를 위한 오픈 소스 시스템
- 컨테이너형 어플리케이션의 관리.
Task
하나의 익스큐터에게 전송되는 단위
Task < Stage < Job
- Job : 스파크 액션에 따라 생성되는 여러 작업으로 구성된 병렬 계산
- Stage : Task 여러개를 묶은 것. 단위에 따라 구분됨
4 | Spark SQL실습
4-01 | DataFrame 이란
스파크는 행으로 구성된 RDD를 데이터 프레임 객체로 확장하고 데이터 프레임으로 작업함
DataFrame 은
- Row 객체를 포함
- 스키마를 갖고 있음
- sql 쿼리 사용
- JSON, Hive, Parquet으로 읽고 쓸 수 있음
- JDBC와 커뮤니케이션 가능함
4-02 | 비교
RDD | DataFrame | Dataset
- 도입 순서 :
- RDD : 1.0
- DataFrame : 1.3
- Dataset : 1.6
- RDD (Resilient Distributed Dataset)
- 분산된 데이터셋의 자료형
- MapReduce를 이용한 병렬 처리
- 연산은 새 데이터셋을 생성하는 transform과 데이터셋에서 계산 수행 후 드라이버 프로그램에 값을 반환하는 action으로 함수가 나눠짐
- DataFrame
- 이름있는 칼럼으로 구성된 데이터셋
- SparkSQL 통해 사용 가능
- 관계형 테이블과 r/python의 데이터프레임과 유사하지만 더 많은 기능 제공함
- Dataset
- 분산된 데이터 모음
- RDD와 DataFrame의 장점을 합함
4-03 | 실습
: SparkSQL로 평점이 낮은 영화 10개 찾기
- 분석할 데이터 셋인 u.item 다운로드 하기
데이터셋 : ml-100k의 movielens 데이터셋
$ mkdir ml-100k
$ cd ml-100k
$ wget http://media.sundog-soft.com/hadoop/ml-100k/u.item
$ wget http://media.sundog-soft.com/hadoop/ml-100k/u.data
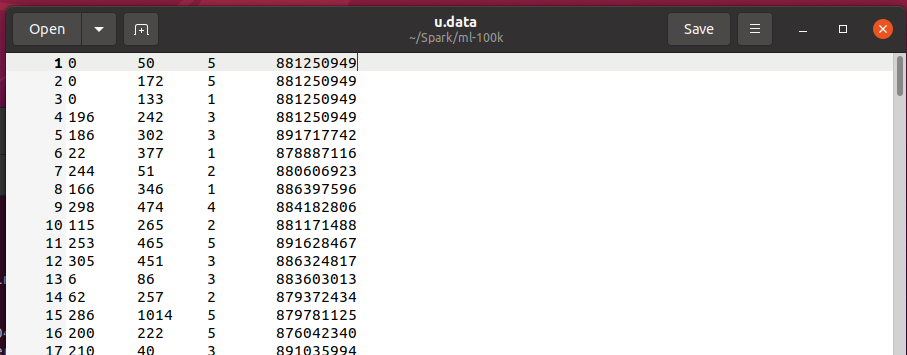
u.data : 평점 데이터셋 (100,000개)
사용자 ID, 영화 ID, 평점(1~5) | 평점의 타임스탬프
user id | movid id | rating | timestamp
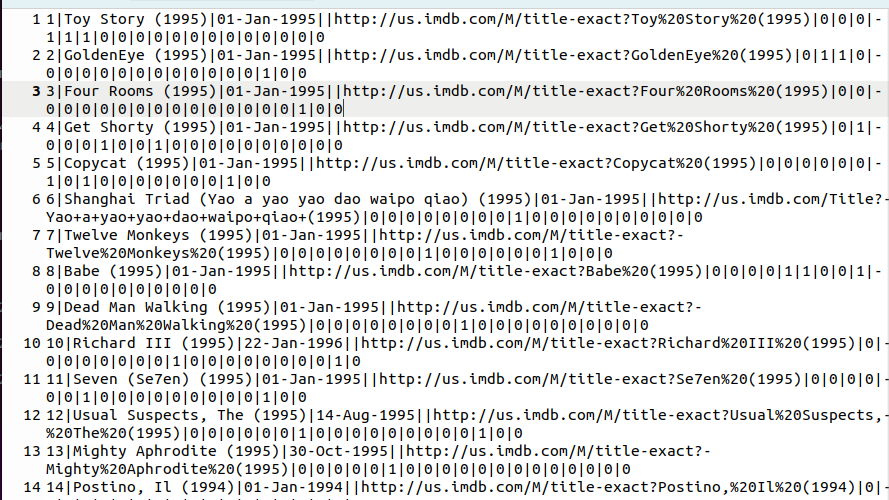
u.item : 영화 데이터셋 (영화ID, 제목 장르)
영화 ID | 영화 이름 (개봉일) | 비디오 개봉일 | IMDb 링크 | | (장르)
movie id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | Crime | Documentary | Drama | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi |Thriller | War | Western |
2. 코드 스크립트 다운로드 후 코드 수정하기
$ wget http://media.sundog-soft.com/hadoop/Spark.zip
$ unzip Spark.zip
!! ml-100k 디렉토리 안에 파이썬 스크립트와 u.data, u.item 데이터셋 위치시키기 !!
3. 스크립트를 열어 데이터셋의 위치 조정후, less 명령어로 실행할 스크립트 내용 확인하기
$ less LowestRatedMovieSpark.py# LowestRatedMovieDataFrame.pyfrom pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
# u.item 을 읽어 movieNames[영화 id] = 영화 제목 딕셔너리 return 해주는 함수
def loadMovieNames():
movieNames = {}
with open("../ml-100k/u.item", encoding="ISO-8859-1") as f:
for line in f:
fields = line.split('|')
movieNames[int(fields[0])] = fields[1] # movieNames[영화 id] = 영화 제목
return movieNames
# 한 줄을 공백을 기준으로 split하여 filed 저장 후, movieID와 rating을 갖는 Dataframe의 Row로 반환
def parseInput(line):
fields = line.split()
return Row(movieID = int(fields[1]), rating = float(fields[2]))
if __name__ == "__main__":
# spark 세션을 생성함
spark = SparkSession.builder.appName("PopularMovies").getOrCreate()
# movieNames[영화 id] = 영화 제목 딕셔너리
movieNames = loadMovieNames() # movieNames[영화 id] = 영화 제목
# Get the raw data
lines = spark.sparkContext.textFile("../ml-100k/u.data")
# (movieID, rating)로 된 행 객체 RDD로 변환
movies = lines.map(parseInput) # RDD
# Convert that to a DataFrame
# RDD를 데이터프레임으로 변환
movieDataset = spark.createDataFrame(movies) # DataFrame
# groupBy로 movie ID를 묶어서 중복 제거 후, 각 영화당 rating칼럼을 기준으로 평균 계산
averageRatings = movieDataset.groupBy("movieID").avg("rating")
# groupBy로 movie ID를 묶은 후 각 영화당 rating개수 카운트
counts = movieDataset.groupBy("movieID").count()
# averageRating와 counts를 join함(movieID, avg(rating), count columns)
averagesAndCounts = counts.join(averageRatings, "movieID")
# 평점 낮은대로 top 10 결과 뽑기
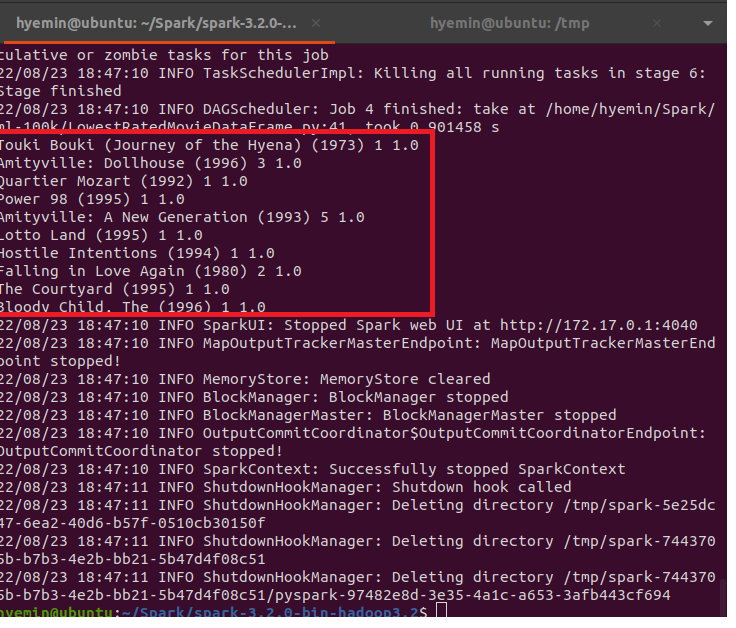
topTen = averagesAndCounts.orderBy("avg(rating)").take(10)
# 결과 출력하기
print (movieNames[movie[0]], movie[1], movie[2])
# Stop the session
spark.stop()
3. spark-submit 명령어로 스크립트를 실행
$ ./bin/spark-submit ../LowestRatedMovieDataFrame.py
./bin/spark-submit (LowestRatedMovieDataFrame.py 경로)
참고자료
사이트
책
The Definitive Guide Spark
강의
Udemy
'#️⃣ Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark Streaming - Twitter 해시태그 분석 (1) (0) | 2022.10.07 |
|---|---|
| [Spark] 이벤트시간 윈도우, 워터마크 (0) | 2022.10.06 |
| [Spark] Ubuntu 21.04에 Spark 설치하기 (0) | 2022.03.14 |
| [Hadoop] Spark란 + 실습 (0) | 2022.03.11 |
| [스파크 완벽 가이드] CH.1_아파치 스파크란 (0) | 2022.02.06 |
이전에 블로그에 정리했던 글을 동아리 스터디를 위해 한 번 더 정리한 글이다.
기록을 위해 블로그에도 남긴다.
이전 정리글 :https://hyem207.tistory.com/43
[Hadoop] Spark란 + 실습
보호되어 있는 글입니다. 내용을 보시려면 비밀번호를 입력하세요.
hyem207.tistory.com
목차
1 | Spark란
2 | Spark 정의 및 등장 배경
2-1 | Spark란
2-2 | Spark 등장 배경
3| Spark Architecture
4 | Spark SQL실습
1 | Spark란
간략 소개
The most widely-used engine for scalable computing
Thousands of companies, including 80% of the Fortune 500, use Apache Spark™.Over 2,000 contributors to the open source project from industry and academia.
Amazon, Ebay, Yahoo 등에서 사용
스파크는 머신러닝 과 같은 복잡한 작업도 가능하며, 데이터 마이닝, 그래프 분석, 스트리밍 데이터도 다룰 수 있다.
자바, 스칼라, 파이썬 등의 프로그래밍 언어 지원하여 스크립트 작성함
무엇보다도 속도도 빠르고 확장 가능한 강력한 프레임워크다. "맵 리듀스와 비교시, 메모리 내에서 작동시 100배, 디스크로 접근 시에는 10배 더 빨라짐" "또한 맵리듀스는 제한적이지만, 스파크는 좀 더 유연하게 사용 가능함" "핫한 기술"
2 | Spark 정의 및 등장 배경
2-1 | Spark란
💡 " A fast and general engine for large-scale data processing" 대규모 데이터를 처리하는 빠른 엔진 (병렬 처리 오픈소스 엔진)
- 통합 컴퓨팅 엔진, 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합 (병렬 처리 오픈소스 엔진)
- 클러스터 : 두 개 이상의 노드에 걸쳐있는 여러 서버 인스턴스 그룹
1) 특징
- 빠른 처리 속도
- 단일 노트북 환경에서부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행 가능
- 빅데이터 처리 쉽게 시작 가능, 엄청난 규모의 클러스터로 확장 가능
- 다양한 프로그래밍 언어 지원
- 다양한 라이브러리 지원
- 높은 호환성
2) Spark의 철학
- 통합
- 혼합형 API를 제공하여 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있음 (다른 라이브러리의 기능을 조합)
- 스파크는 통합 엔진을 제공하면서 빠르게 빅데이터 분석 업무의 표준이 됨
- 컴퓨터 엔진
- 스파크는 통합이라는 관점을 중시하면서 컴퓨팅 엔진으로 제한해 옴
- 스파크는 데이터 연산만 수행할 뿐 영구 저장소 역할은 수행하지 않음. 대신 클라우드 기반의 저장소를 지원함.→ 이는 데이터 저장 위치에 상관없이 처리에 집중되도록 만들어 짐
- 라이브러리
- 스파크에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 올라온 다양한 외부 라이브러리를 지원함
2-2 | Spark 등장 배경
💡 첫 시작 : UC버클리 대학교에서 2009년 스파크 연구 프로젝트로 시작되어 다음 해에 UC 버클리 대학교 AMPlab 소속에서 낸 논문으로 스파크를 처음 세상에 알리게 됨 → Spark는 이후에도 꾸준히 확장 중
1) 만들어진 당시 상황
하둡 맵 리듀스는 대규모 클러스터에서 병렬로 데이터를 처리하기 위한 최초의 오픈 소스 시스템
하지만 다음과 같은 문제점이 있었음
- 맵 리듀스로 처리하려면 단계별로 맵 리듀스 잡을 개발하고 클러스터에서 각각 실행해야 하므로 매번 데이터를 처음부터 읽어야 했음
⇒ Spark 등장 : 함수형 프로그래밍 기반의 API, 새로운 엔진 기반의 API를 구현함
📢 Spark VS 맵 리듀스 속도 비교
스파크는 인메모리 기반의 처리로 맵리듀스 작업처리에 비해 디스크는 10배, 메모리 작업은 100배 빠름
원인 : 작업의 중간 결과 저장 장소
- 맵 리듀스 : 디스크
- Spark : 메모리
2) Spark의 발전
- 스파크의 첫 버전은 배치 애플리케이션만 지원하다가, 스칼라 인터프리터를 스파크에 접목하여 매우 유용한 대화형 시스템을 제공할 수 있게 됨
- → 이러한 사용에서 문제점을 정리하여 더 범용적인 컴퓨팅 플랫폼을 설계함
- 조합형 API의 핵심 아이디어
- 1.0 이전
- 초기 버전은 함수형 연산 관점에서 API 정의
- 1.0 이후
- 구조화된 데이터를 기반으로 동작하는 신규 API인 스파크 SQL 추가됨
- 이후 DataFrame, 머신러닝 파이프라인, 구조적 스트리밍 등 더 강력한 구조체 기반의 신규 API를 추가함
- 2013년에 AMPlab은 스파크가 특정 업체에 종속되는 것을 막기 위해 아파치 재단에 기부함 & 초기 팀은 프로젝트를 성장시키기 위해 '데이터브릭스'를 설립함.
3 | Spark Architecture
3-1 | Spark 기본 아키텍처
💡 Spark는 클러스터의 데이터 처리 작업을 관리하고 조율함.
*클러스터 : 여러 컴퓨터의 자원을 모아 하나의 컴퓨터처럼 사용할 수 있게 만듦
구성 요소
크게 Driver와 Executer로 구성됨
클러스터 매니저 : 연산에 사용할 클러스터(자원) 관리
- 클러스터 매니저 ‘자원할당’ 흐름
- 사용자가 클러스터 매니저에 스파크 애플리케이션을 제출함 → 클러스터 매니저가 애플리케이션에 필요한 자원 할당 → 할당받은 자원으로 작업 처리
드라이버 프로세스 : 스파크 애플리케이션의 심장. 클러스터 노드 중 하나로 main() 실행
: SparkContext 객체 생성
역할 :
- 애플리케이션의 수명 주기 동안 관련 정보 모두 유지
- 사용자 프로그램/입력에 대한 응답
- 전반적인 익스큐터 프로세스 작업과 관련된 분석/배포/스케줄링 수행
익스큐터 : 드라이버 프로세스가 할당한 작업 수행
- 역할 :
- 드라이버가 할당한 코드를 실행
- 진행상황을 다시 드라이버 노드에 보고
스파크 어플리케이션
스파크 실행 프로그램
드라이버와 익스큐터로 실행되는 프로그램
SparkSession(드라이버 프로세스)로 제어함
SparkSession (SparkContext)
클러스터 매니저와 연결되는 객체
클러스터 매니저
스파크 어플리케이션의 자원 분배
유형
- StandAlone– Spark에 포함된 심플한 클러스터 매니저를 통해
- 클러스터를 쉽게 설정할 수 있습니다.
- Apache Mesos – Hadoop MapReduce도 실행할 수 있는 일반 클러스터 관리자 및 서비스 어플리케이션(권장되지 않음)
- Hadoop WARN – Hadoop 2 및 3의 리소스 관리자.
- Kubernetes – 도입, 확장, 확장 자동화를 위한 오픈 소스 시스템
- 컨테이너형 어플리케이션의 관리.
Task
하나의 익스큐터에게 전송되는 단위
Task < Stage < Job
- Job : 스파크 액션에 따라 생성되는 여러 작업으로 구성된 병렬 계산
- Stage : Task 여러개를 묶은 것. 단위에 따라 구분됨
4 | Spark SQL실습
4-01 | DataFrame 이란
스파크는 행으로 구성된 RDD를 데이터 프레임 객체로 확장하고 데이터 프레임으로 작업함
DataFrame 은
- Row 객체를 포함
- 스키마를 갖고 있음
- sql 쿼리 사용
- JSON, Hive, Parquet으로 읽고 쓸 수 있음
- JDBC와 커뮤니케이션 가능함
4-02 | 비교
RDD | DataFrame | Dataset
- 도입 순서 :
- RDD : 1.0
- DataFrame : 1.3
- Dataset : 1.6
- RDD (Resilient Distributed Dataset)
- 분산된 데이터셋의 자료형
- MapReduce를 이용한 병렬 처리
- 연산은 새 데이터셋을 생성하는 transform과 데이터셋에서 계산 수행 후 드라이버 프로그램에 값을 반환하는 action으로 함수가 나눠짐
- DataFrame
- 이름있는 칼럼으로 구성된 데이터셋
- SparkSQL 통해 사용 가능
- 관계형 테이블과 r/python의 데이터프레임과 유사하지만 더 많은 기능 제공함
- Dataset
- 분산된 데이터 모음
- RDD와 DataFrame의 장점을 합함
4-03 | 실습
: SparkSQL로 평점이 낮은 영화 10개 찾기
- 분석할 데이터 셋인 u.item 다운로드 하기
데이터셋 : ml-100k의 movielens 데이터셋
$ mkdir ml-100k
$ cd ml-100k
$ wget http://media.sundog-soft.com/hadoop/ml-100k/u.item
$ wget http://media.sundog-soft.com/hadoop/ml-100k/u.data
u.data : 평점 데이터셋 (100,000개)
사용자 ID, 영화 ID, 평점(1~5) | 평점의 타임스탬프
user id | movid id | rating | timestamp
u.item : 영화 데이터셋 (영화ID, 제목 장르)
영화 ID | 영화 이름 (개봉일) | 비디오 개봉일 | IMDb 링크 | | (장르)
movie id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | Crime | Documentary | Drama | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi |Thriller | War | Western |
2. 코드 스크립트 다운로드 후 코드 수정하기
$ wget http://media.sundog-soft.com/hadoop/Spark.zip
$ unzip Spark.zip!! ml-100k 디렉토리 안에 파이썬 스크립트와 u.data, u.item 데이터셋 위치시키기 !!
3. 스크립트를 열어 데이터셋의 위치 조정후, less 명령어로 실행할 스크립트 내용 확인하기
$ less LowestRatedMovieSpark.py# LowestRatedMovieDataFrame.pyfrom pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql import functions
# u.item 을 읽어 movieNames[영화 id] = 영화 제목 딕셔너리 return 해주는 함수
def loadMovieNames():
movieNames = {}
with open("../ml-100k/u.item", encoding="ISO-8859-1") as f:
for line in f:
fields = line.split('|')
movieNames[int(fields[0])] = fields[1] # movieNames[영화 id] = 영화 제목
return movieNames
# 한 줄을 공백을 기준으로 split하여 filed 저장 후, movieID와 rating을 갖는 Dataframe의 Row로 반환
def parseInput(line):
fields = line.split()
return Row(movieID = int(fields[1]), rating = float(fields[2]))
if __name__ == "__main__":
# spark 세션을 생성함
spark = SparkSession.builder.appName("PopularMovies").getOrCreate()
# movieNames[영화 id] = 영화 제목 딕셔너리
movieNames = loadMovieNames() # movieNames[영화 id] = 영화 제목
# Get the raw data
lines = spark.sparkContext.textFile("../ml-100k/u.data")
# (movieID, rating)로 된 행 객체 RDD로 변환
movies = lines.map(parseInput) # RDD
# Convert that to a DataFrame
# RDD를 데이터프레임으로 변환
movieDataset = spark.createDataFrame(movies) # DataFrame
# groupBy로 movie ID를 묶어서 중복 제거 후, 각 영화당 rating칼럼을 기준으로 평균 계산
averageRatings = movieDataset.groupBy("movieID").avg("rating")
# groupBy로 movie ID를 묶은 후 각 영화당 rating개수 카운트
counts = movieDataset.groupBy("movieID").count()
# averageRating와 counts를 join함(movieID, avg(rating), count columns)
averagesAndCounts = counts.join(averageRatings, "movieID")
# 평점 낮은대로 top 10 결과 뽑기
topTen = averagesAndCounts.orderBy("avg(rating)").take(10)
# 결과 출력하기
print (movieNames[movie[0]], movie[1], movie[2])
# Stop the session
spark.stop()
3. spark-submit 명령어로 스크립트를 실행
$ ./bin/spark-submit ../LowestRatedMovieDataFrame.py
./bin/spark-submit (LowestRatedMovieDataFrame.py 경로)참고자료
사이트
책
The Definitive Guide Spark
강의
Udemy
'#️⃣ Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark Streaming - Twitter 해시태그 분석 (1) (0) | 2022.10.07 |
|---|---|
| [Spark] 이벤트시간 윈도우, 워터마크 (0) | 2022.10.06 |
| [Spark] Ubuntu 21.04에 Spark 설치하기 (0) | 2022.03.14 |
| [Hadoop] Spark란 + 실습 (0) | 2022.03.11 |
| [스파크 완벽 가이드] CH.1_아파치 스파크란 (0) | 2022.02.06 |