
01 | 아파치 스파크
스파크(Spark)란
통합 컴퓨팅 엔진, 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합 (병렬 처리 오픈소스 엔진)
* 클러스터 : 두 개 이상의 노드에 걸쳐있는 여러 서버 인스턴스 그룹
특징 및 구성
- 단일 노트북 환경에서부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행 가능
-> 빅데이터 처리 쉽게 시작 가능, 엄청난 규모의 클러스터로 확장 가능
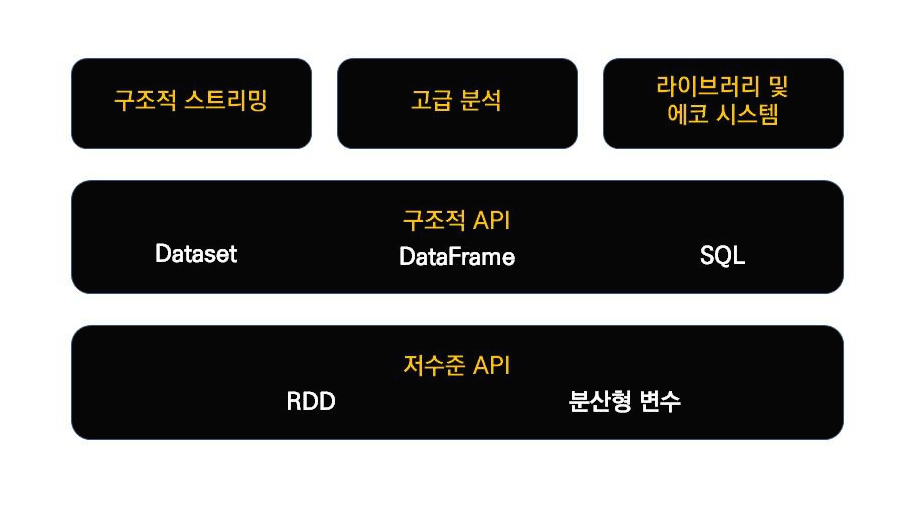
아래는 스파크의 기능 구성이다.
02 | 아파치 스파크의 철학
01. 통합
스파크는 간단한 데이터 읽기에서부터 SQL 처리, 머신러닝 그리고 스트림 처리에 이르기까지 다양한 데이터 분석 작업과 같은 연산 엔진과 일관성 있는 API를 수행할 수 있도록 설계됨
- 혼합형 API를 제공하여 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있음
- 또한 스파크 API는 사용자 애플리케이션에서 다른 라이브러리의 기능을 조합해 더 나은 성능을 발휘할 수 있도록 설계됨
- 스파크는 통합 엔진을 제공하면서 빠르게 빅데이터 분석 업무의 표준이 됨
컴퓨팅 엔진
스파크는 통합이라는 관점을 중시하면서 컴퓨팅 엔진으로 제한해 옴
- 스파크는 데이터 연산하는 역할만 수행할 뿐 영구 저장소 역할은 수행하지 않음
대신 클라우드 기반의 저장소를 지원함.
→ 이는 데이터 저장 위치에 상관없이 처리에 집중되도록 만들어 짐
즉, 스파크는 연산 기능에 초점을 맞추면서 아파치 하둡 같은 기존 빅데이터 플랫폼과는 차별화함.
하둡의 경우는 구조상 다른 저장소에 접근하는 애플리케이션을 개발하기 어려운데, 스파크는 하둡 저장소와 잘 호환이 된다.
라이브러리
스파크에서 제공하는 표준 라이브러리와 오픈소스 카뮤니티에서 올라온 다양한 외부 라이브러리를 지원함
03 | 스파크의 등장 배경
2005년 전
많은 연산과 대규모 데이터 처리를 프로세서의 성능 향상에 맡김
그 이후
2005년 경에 하드웨어 성능 향상이 방열 한계로 멈추면서 병렬 Cpup 코어를 더 많이 추가하는 방향으로 진화함
이는 병렬 처리를 요구함
결과적으로 데이터 수집 비용은 저렴해졌지만, 데이터는 클러스터에서 처리해야 할 만큼 거대해짐
따라서 새로운 프로그래밍 모델이 필요해졌으며 이런 문제를 해결하기 위해 아파치 스파크가 탄생함
04 | 스파크의 역사
시작은 UC버클리 대학교에서 2009년 스파크 연구 프로젝트로 시작되어 다음 해에 UC 버클리 대학교 AMPlab 소속에서 낸 논문으로 스파크를 처음 세상에 알리게 됨. 이후 스파크는 신규 프로젝트를 내며 스파크의 영역을 꾸준히 넓혀가고 있음
(한 가지 예시로 구조적 스트리밍 엔진으로 이는 거대한 규모의 데이터 셋을 처리하기 위해 주로 사용된다.)
만들어진 당시 상황
하둡 맵 리듀스는 대규모 클러스터에서 병렬로 데이터를 처리하기 위한 최초의 오픈 소스 시스템임.
하지만 다음과 같은 문제점이 있었음
- 맵 리듀스로 처리하려면 단계별로 맵 리듀스 잡을 개발하고 클러스터에서 각각 실행해야 하므로 매번 데이터를 처음부터 읽어야 했음
이를 해결하기 위해 여러 단계로 이루어진 애플리케이션을 간결하게 개발할 수 있는 함수형 프로그래밍 기반의 API를 설계함 .
또한 연산 단계 사이에서 메모리에 저장된 데이터를 효율적으로 공유할 수 있는 새로운 엔진 기반의 API를 구현함
스파크의 첫 버전은 배치 애플리케이션만 지원하다가, 스칼라 인터프리터를 스파크에 접목하여 매우 유용한 대화형 시스템을 제공할 수 있게 됨
이러한 사용에서 문제점을 정리하여 더 범용적인 컴퓨팅 플랫폼을 설계함
2013년에 AMPlab은 스파크가 특정 업체에 종속되는 것을 막기 위해 아파치 재단에 기부함.
초기 팀은 프로젝트를 성장시키기 위해 '데이터브릭스'를 설립함.
조합형 API의 핵심 아이디어
1.0 이전
초기 버전은 함수형 연산 과점에서 API 정의
1.0 이후
구조화된 데이터를 기반으로 동작하는 신규 API인 스파크 SQL이 추가됨
이후 DataFrame, 머신러닝 파이프라인, 구조적 스트리밍 등 더 강력한 구조체 기반의 신규 API를 추가함
* 스파크 SQL : 데이터 포맷과 코드를 잘 이해하는 라이브러리와 API를 이용해 새롭고 강력한 최적화 기능을 제공함
05 | 스파크 실행하기
스파크는 파이썬, 자바, 스칼라, R 그리고 SQL 언어에서 사용할 수 있으며,
스파크는 스칼라로 구현되어 자바 가상 머신 기반으로 동작한다.
로컬환경에서 스파크를 다운로드 가능하다 (다만 자바 설치 되어 있어야 함)
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides additional pre-built distribut
spark.apache.org
위 글은 책 '스파크 완벽 가이드'를 읽고 정리한 글입니다.
'#️⃣ Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark Streaming - Twitter 해시태그 분석 (1) (0) | 2022.10.07 |
|---|---|
| [Spark] 이벤트시간 윈도우, 워터마크 (0) | 2022.10.06 |
| [Spark] Spark란 + 실습 (추가 정리) (0) | 2022.10.06 |
| [Spark] Ubuntu 21.04에 Spark 설치하기 (0) | 2022.03.14 |
| [Hadoop] Spark란 + 실습 (0) | 2022.03.11 |
01 | 아파치 스파크
스파크(Spark)란
통합 컴퓨팅 엔진, 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합 (병렬 처리 오픈소스 엔진)
* 클러스터 : 두 개 이상의 노드에 걸쳐있는 여러 서버 인스턴스 그룹
특징 및 구성
- 단일 노트북 환경에서부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행 가능
-> 빅데이터 처리 쉽게 시작 가능, 엄청난 규모의 클러스터로 확장 가능
아래는 스파크의 기능 구성이다.
02 | 아파치 스파크의 철학
01. 통합
스파크는 간단한 데이터 읽기에서부터 SQL 처리, 머신러닝 그리고 스트림 처리에 이르기까지 다양한 데이터 분석 작업과 같은 연산 엔진과 일관성 있는 API를 수행할 수 있도록 설계됨
- 혼합형 API를 제공하여 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있음
- 또한 스파크 API는 사용자 애플리케이션에서 다른 라이브러리의 기능을 조합해 더 나은 성능을 발휘할 수 있도록 설계됨
- 스파크는 통합 엔진을 제공하면서 빠르게 빅데이터 분석 업무의 표준이 됨
컴퓨팅 엔진
스파크는 통합이라는 관점을 중시하면서 컴퓨팅 엔진으로 제한해 옴
- 스파크는 데이터 연산하는 역할만 수행할 뿐 영구 저장소 역할은 수행하지 않음
대신 클라우드 기반의 저장소를 지원함.
→ 이는 데이터 저장 위치에 상관없이 처리에 집중되도록 만들어 짐
즉, 스파크는 연산 기능에 초점을 맞추면서 아파치 하둡 같은 기존 빅데이터 플랫폼과는 차별화함.
하둡의 경우는 구조상 다른 저장소에 접근하는 애플리케이션을 개발하기 어려운데, 스파크는 하둡 저장소와 잘 호환이 된다.
라이브러리
스파크에서 제공하는 표준 라이브러리와 오픈소스 카뮤니티에서 올라온 다양한 외부 라이브러리를 지원함
03 | 스파크의 등장 배경
2005년 전
많은 연산과 대규모 데이터 처리를 프로세서의 성능 향상에 맡김
그 이후
2005년 경에 하드웨어 성능 향상이 방열 한계로 멈추면서 병렬 Cpup 코어를 더 많이 추가하는 방향으로 진화함
이는 병렬 처리를 요구함
결과적으로 데이터 수집 비용은 저렴해졌지만, 데이터는 클러스터에서 처리해야 할 만큼 거대해짐
따라서 새로운 프로그래밍 모델이 필요해졌으며 이런 문제를 해결하기 위해 아파치 스파크가 탄생함
04 | 스파크의 역사
시작은 UC버클리 대학교에서 2009년 스파크 연구 프로젝트로 시작되어 다음 해에 UC 버클리 대학교 AMPlab 소속에서 낸 논문으로 스파크를 처음 세상에 알리게 됨. 이후 스파크는 신규 프로젝트를 내며 스파크의 영역을 꾸준히 넓혀가고 있음
(한 가지 예시로 구조적 스트리밍 엔진으로 이는 거대한 규모의 데이터 셋을 처리하기 위해 주로 사용된다.)
만들어진 당시 상황
하둡 맵 리듀스는 대규모 클러스터에서 병렬로 데이터를 처리하기 위한 최초의 오픈 소스 시스템임.
하지만 다음과 같은 문제점이 있었음
- 맵 리듀스로 처리하려면 단계별로 맵 리듀스 잡을 개발하고 클러스터에서 각각 실행해야 하므로 매번 데이터를 처음부터 읽어야 했음
이를 해결하기 위해 여러 단계로 이루어진 애플리케이션을 간결하게 개발할 수 있는 함수형 프로그래밍 기반의 API를 설계함 .
또한 연산 단계 사이에서 메모리에 저장된 데이터를 효율적으로 공유할 수 있는 새로운 엔진 기반의 API를 구현함
스파크의 첫 버전은 배치 애플리케이션만 지원하다가, 스칼라 인터프리터를 스파크에 접목하여 매우 유용한 대화형 시스템을 제공할 수 있게 됨
이러한 사용에서 문제점을 정리하여 더 범용적인 컴퓨팅 플랫폼을 설계함
2013년에 AMPlab은 스파크가 특정 업체에 종속되는 것을 막기 위해 아파치 재단에 기부함.
초기 팀은 프로젝트를 성장시키기 위해 '데이터브릭스'를 설립함.
조합형 API의 핵심 아이디어
1.0 이전
초기 버전은 함수형 연산 과점에서 API 정의
1.0 이후
구조화된 데이터를 기반으로 동작하는 신규 API인 스파크 SQL이 추가됨
이후 DataFrame, 머신러닝 파이프라인, 구조적 스트리밍 등 더 강력한 구조체 기반의 신규 API를 추가함
* 스파크 SQL : 데이터 포맷과 코드를 잘 이해하는 라이브러리와 API를 이용해 새롭고 강력한 최적화 기능을 제공함
05 | 스파크 실행하기
스파크는 파이썬, 자바, 스칼라, R 그리고 SQL 언어에서 사용할 수 있으며,
스파크는 스칼라로 구현되어 자바 가상 머신 기반으로 동작한다.
로컬환경에서 스파크를 다운로드 가능하다 (다만 자바 설치 되어 있어야 함)
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides additional pre-built distribut
spark.apache.org
위 글은 책 '스파크 완벽 가이드'를 읽고 정리한 글입니다.
'#️⃣ Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark Streaming - Twitter 해시태그 분석 (1) (0) | 2022.10.07 |
|---|---|
| [Spark] 이벤트시간 윈도우, 워터마크 (0) | 2022.10.06 |
| [Spark] Spark란 + 실습 (추가 정리) (0) | 2022.10.06 |
| [Spark] Ubuntu 21.04에 Spark 설치하기 (0) | 2022.03.14 |
| [Hadoop] Spark란 + 실습 (0) | 2022.03.11 |